La inteligencia artificial promete automatizar tareas, responder consultas complejas y acelerar procesos empresariales. Sin embargo, muchas organizaciones descubren rápidamente una realidad frustrante: sus agentes de IA son lentos, inconsistentes y generan más espera de la esperada.
El problema no siempre está en el modelo de lenguaje. En constructoras, despachos jurídicos, clínicas y empresas técnicas, la verdadera causa suele encontrarse en la infraestructura que alimenta esos sistemas: almacenamiento ineficiente, redes saturadas, dependencias de APIs externas o arquitecturas mal diseñadas.
Aviso de transparencia: En este blog recomendamos hardware y herramientas que consideramos de calidad para nuestros lectores. Si compras a través de algunos de los enlaces de este artículo, recibimos una pequeña comisión sin que esto te suponga ningún coste adicional. Como Afiliado de Amazon, percibo ingresos por las compras adscritas que cumplen los requisitos aplicables.
La buena noticia es que existe una solución. Comprender dónde se origina la latencia permite construir entornos de IA más rápidos, seguros y económicamente sostenibles mediante infraestructura local, nube privada y estrategias de soberanía digital. Como Recuperar el control de tu información.
¿Qué es realmente la latencia en IA?
La latencia es el tiempo que transcurre entre una solicitud y la primera respuesta que recibe el usuario.
En inteligencia artificial existe una métrica especialmente importante:
Time to First Token (TTFT)
El TTFT mide cuánto tarda un modelo en generar la primera palabra después de recibir una consulta.
Aunque parezca un detalle menor, unos pocos segundos adicionales pueden convertir una herramienta productiva en una experiencia frustrante para los usuarios.
Por ejemplo:
|
Tiempo hasta la primera respuesta (TTFT) |
Percepción del usuario |
Impacto en la productividad |
|
Menos de 1 segundo |
Instantáneo |
Flujo de trabajo continuo y máxima eficiencia. |
|
1 a 3 segundos |
Aceptable |
El usuario mantiene el ritmo de trabajo sin interrupciones significativas. |
|
3 a 5 segundos |
Molesto |
Se producen pausas frecuentes que reducen la concentración y la velocidad de ejecución. |
|
Más de 5 segundos |
Frustrante |
Interrumpe procesos, disminuye la adopción de la herramienta y genera pérdida de productividad. |
El coste oculto de los segundos: ¿Por qué tus agentes de IA frustran a tu equipo?
Cuando un arquitecto consulta planos mediante IA, un abogado busca cláusulas en contratos o una clínica necesita acceder rápidamente a historiales médicos, cada segundo cuenta.
La acumulación de retrasos provoca:
- Menor productividad.
- Interrupciones constantes.
- Pérdida de concentración.
- Menor adopción de la tecnología.
- Costos operativos ocultos.
Muchas empresas creen que necesitan comprar hardware más potente, pero el verdadero problema suele encontrarse en otra parte.
El cuello de botella del Time to First Token en la nube pública
La mayoría de agentes modernos dependen de múltiples servicios externos:
- APIs de modelos de lenguaje.
- Bases de datos vectoriales remotas.
- Sistemas SaaS.
- Servicios de sincronización.
Cada consulta realiza múltiples viajes entre la empresa y servidores externos.
Ese recorrido añade:
- Latencia de red.
- Congestión de internet.
- Limitaciones de proveedores.
- Throttling de APIs.
- Dato rompe-mitos
Mito:
Para tener agentes rápidos necesitas GPUs extremadamente costosas o contratar planes empresariales de IA en la nube.
Realidad:
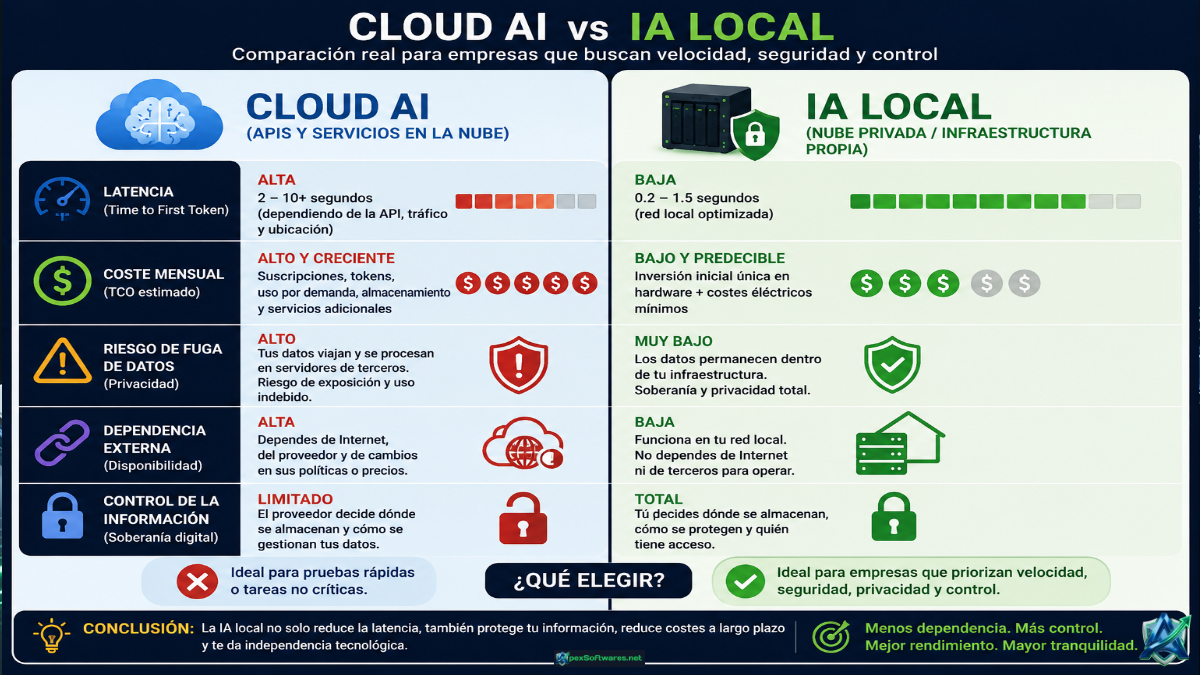
Gran parte de la latencia proviene del recorrido de los datos y no del procesamiento del modelo.
Un Modelo de Lenguaje Pequeño (SLM) optimizado ejecutándose localmente puede responder más rápido que soluciones cloud para tareas específicas del negocio.
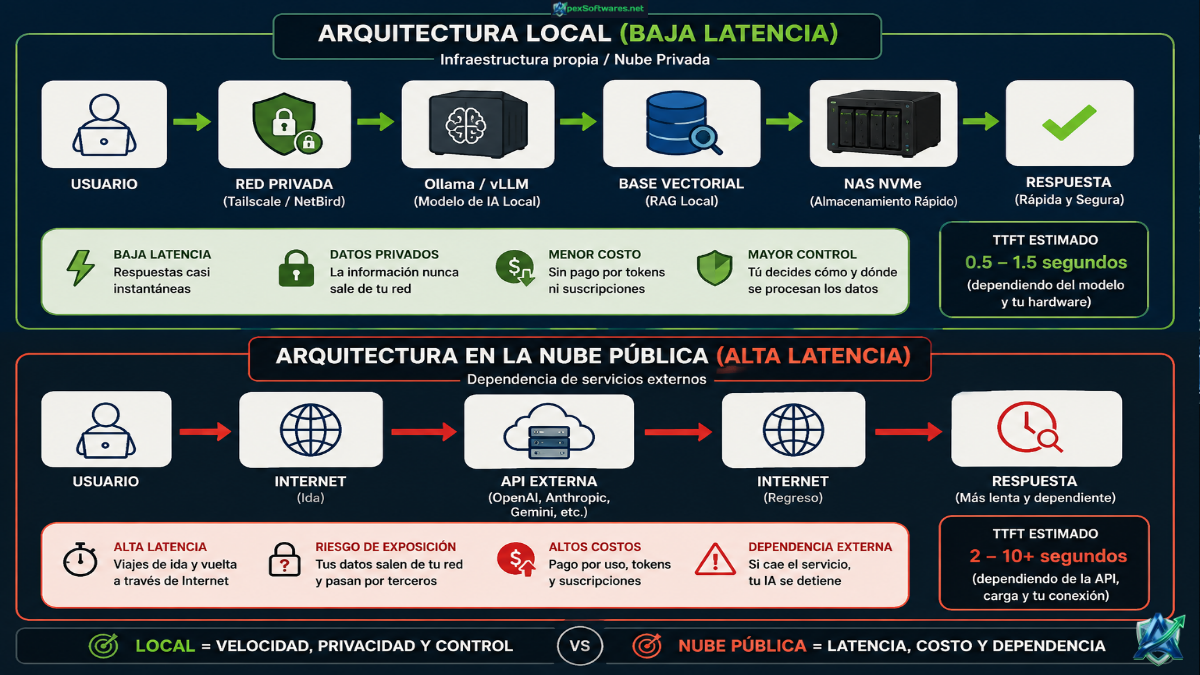
La anatomía del retraso: APIs comerciales vs Infraestructura Local
APIs comerciales
Flujo típico:
- Usuario → Internet → API → Procesamiento → Internet → Usuario
- Cada salto añade tiempo.
Infraestructura local
Flujo típico:
- Usuario → Red privada → Servidor IA → Respuesta
- Menos intermediarios.
- Menos dependencia externa.
- Menor latencia.
- Mayor control.
El peligro de enviar tus datos sensibles fuera del perímetro de la empresa
Muchas organizaciones alimentan modelos públicos con:
- Contratos.
- Estados financieros.
- Diseños CAD.
- Planos arquitectónicos.
- Información médica.
- Documentación estratégica.
Esto genera riesgos de:
Fuga por contexto
La información sale del entorno corporativo para ser procesada por terceros.
Problemas regulatorios
Dependiendo del sector, puede existir incumplimiento de:
- Auditorías internas.
- Normativas de privacidad.
- Políticas de seguridad corporativa.
Dependencia tecnológica
Si la API falla, toda la automatización se detiene.
Soberanía Digital: La velocidad real se construye dentro de tu propia nube privada
La soberanía digital consiste en mantener el control sobre:
- Los datos.
- La infraestructura.
- Los accesos.
- Las copias de seguridad.
No se trata únicamente de privacidad.
También se trata de rendimiento.
ser dueño de tus propios datos
Optimizando RAG local para respuestas instantáneas
El modelo RAG (Retrieval-Augmented Generation) permite que la IA consulte documentación empresarial antes de responder.
Por ejemplo:
- Contratos legales.
- Expedientes médicos.
- Planos constructivos.
- Manuales técnicos.
Cuando el almacenamiento es lento, el agente también será lento.
Por eso las implementaciones modernas utilizan:
- Ollama
- vLLM
- LangGraph
- CrewAI
- Bases vectoriales locales
alimentadas por almacenamiento NVMe de alto rendimiento.
Reducción de costes y latencia con almacenamiento NVMe
Los discos NVMe modernos ofrecen:
- Acceso casi instantáneo.
- Menor tiempo de búsqueda.
- Mayor capacidad de procesamiento concurrente.
En entornos basados en TrueNAS, el uso de pools ZFS optimizados reduce significativamente los tiempos de recuperación documental.
Cómo saber si este problema te está afectando
Checklist de diagnóstico
- ✔ Tus agentes tardan varios segundos en responder.
- ✔ Los usuarios se quejan de lentitud.
- ✔ Dependes completamente de APIs externas.
- ✔ Manejas información sensible.
- ✔ Los costes mensuales siguen aumentando.
- ✔ No sabes dónde se almacenan realmente los datos.
- ✔ Tu IA deja de funcionar cuando falla internet.
- ✔ No tienes infraestructura propia para IA.
Si marcaste tres o más puntos, probablemente existe un problema de latencia o arquitectura.
Lo que puede ocurrir si no solucionas este problema
Pérdida de productividad
Los usuarios abandonan herramientas lentas.
Costos ocultos
- Más suscripciones.
- Más dependencia.
- Más consumo de recursos.
Riesgos de seguridad
Mayor exposición de información crítica.
Interrupciones operativas
La caída de un proveedor puede paralizar procesos completos.
Menor competitividad
Las empresas más rápidas toman mejores decisiones.
¿No sabes si este problema está afectando a tu empresa?
En ApexSoftwares realizamos auditorías de infraestructura, almacenamiento y respaldo para identificar cuellos de botella, riesgos de seguridad y oportunidades de optimización en entornos de inteligencia artificial empresarial.
El riesgo del “Hazlo Tú Mismo” en IA empresarial
Muchas empresas logran instalar un modelo en Docker durante un fin de semana.
El problema aparece cuando intentan llevarlo a producción.
Error 1: Ignorar el almacenamiento
La IA es tan rápida como los datos que consume.
Error 2: Exponer servicios a Internet
Abre nuevas superficies de ataque.
Error 3: No implementar copias de seguridad
Un fallo o ransomware puede destruir meses de trabajo.
Soluciones profesionales para acelerar agentes de IA
Una estrategia sólida suele combinar:
- Nube privada empresarial.
- NAS de alto rendimiento.
- Almacenamiento NVMe.
- TrueNAS SCALE.
- Redes privadas con Tailscale o NetBird.
- RAG local.
- Copias de seguridad automatizadas.
- Acceso remoto seguro.
El objetivo no es únicamente tener una IA más rápida.
Es disponer de una infraestructura confiable, segura y preparada para crecer.
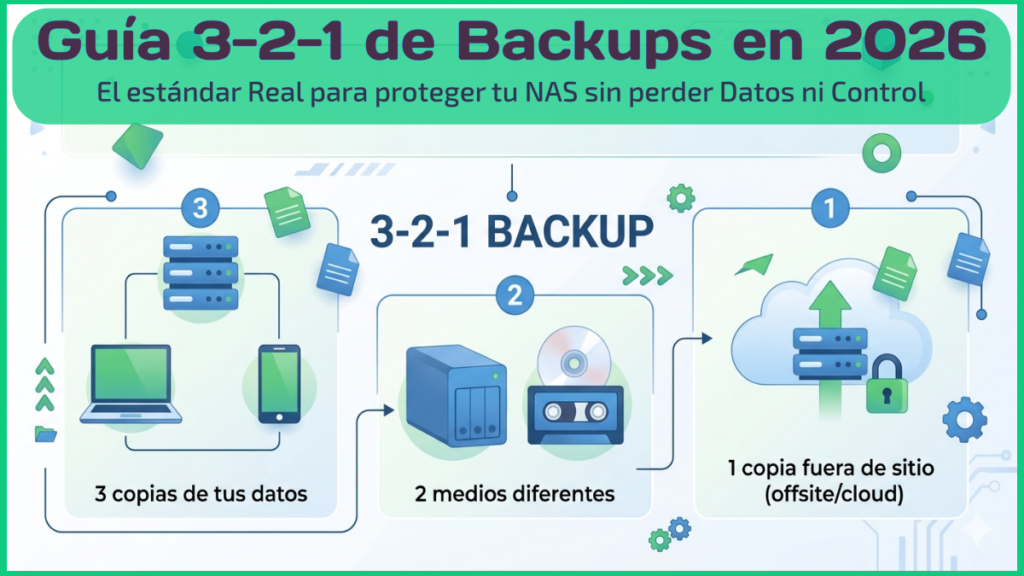
Estrategia profesional de copias de seguridad
Preguntas Frecuentes
¿Qué es el Time to First Token (TTFT)?
Es el tiempo que tarda una IA en generar la primera palabra después de recibir una consulta.
¿La lentitud siempre es culpa del modelo?
No. Frecuentemente el problema está en la red, el almacenamiento o la arquitectura.
¿Una IA local puede ser más rápida que una API comercial?
Sí, especialmente cuando utiliza modelos optimizados para tareas específicas.
¿Qué es RAG local?
Es una arquitectura donde la IA consulta documentos internos antes de responder.
¿Necesito una GPU muy costosa?
No necesariamente. Muchas cargas empresariales funcionan eficientemente con modelos optimizados.
¿Qué ventajas tiene una nube privada?
Mayor control, seguridad, privacidad y menor dependencia de terceros.
¿TrueNAS sirve para proyectos de IA?
Sí. Es una plataforma muy utilizada para almacenamiento empresarial y RAG local.
¿La IA local mejora la soberanía digital?
Sí. Permite mantener datos y procesos dentro de la organización.
Conclusión
La mayoría de los problemas de rendimiento en inteligencia artificial no se originan en el modelo, sino en la infraestructura que lo rodea.
Una arquitectura mal diseñada puede generar retrasos, aumentar costes, exponer información sensible y limitar la adopción de la IA dentro de la empresa.
Por el contrario, una estrategia basada en nube privada, almacenamiento centralizado, RAG local y soberanía digital permite construir sistemas más rápidos, seguros y sostenibles a largo plazo.
La velocidad importa. Pero el control de la información importa aún más.
Auditoría de Infraestructura para IA Local y Nube Privada
¿Tus agentes de IA responden lento, generan costes crecientes o dependen completamente de servicios externos?
En ApexSoftwares analizamos tu infraestructura actual, identificamos cuellos de botella y diseñamos soluciones seguras basadas en nube privada, almacenamiento empresarial y soberanía digital.
Solicitar Auditoría de Infraestructura Empresarial
Artículos Relacionados